文章目录
- 1、常见访问路径
- 1.1、TABLE ACCESS FULL
- 1.2、TABLE ACCESS BY USER ROWID
- 1.3、TABLE ACCESS BY ROWID RANGE
- 1.4、TABLE ACCESS BY INDEX ROWID
- 1.5、INDEX UNIQUE SCAN
- 1.6、INDEX RANGE SCAN
- 1.7、INDEX SKIP SCAN
- 1.8、INDEX FULL SCAN
- 1.9、INDEX FAST FULL SCAN
- 1.10、INDEX FULL SCAN(MIN/MAX)
- 1.11、MAT_VIEW REWRITE ACCESS FULL
- 2、单块读与多块读
- 3、为什么有时候索引扫描比全表扫描更慢
- 4、DML对于索引维护的影响
访问路径指的就是通过哪种扫描方式获取数据,比如全表扫描、索引扫描或者直接通过ROWID获取数据。想要成为SQL优化高手,我们就必须深入理解各种访问路径。
1、常见访问路径
1.1、TABLE ACCESS FULL
TABLE ACCESS FULL表示全表扫描,一般情况下是多块读,HINT: FULL(表名/别名)。等待事件为db file scattered read。如果是并行全表扫描,等待事件为direct path read。在Oracle11g中有个新特征,在对一个大表进行全表扫描的时候,会将表直接读入PGA,绕过buffer cache,这个时候全表扫描的等待事件也是direct path read。一般情况下,我们都会禁用该新特征。等待事件direct path read在开启了异步I/O(disk_asynch_io)的情况下统计是不准确的。
因为direct path read统计不准,所以我们禁用了direct path read。
alter system set "_serial_direct_read"=false;
全表扫描究竟是怎么扫描数据的呢?回忆一下Oracle的逻辑存储结构,Oracle最小的存储单位是块(block),物理上连续的块组成了区(extent),区又组成了段(segment)。对于非分区表,如果表中没有clob/blob字段,那么一个表就是一个段。全表扫描,其实就是扫描表中所有格式化过的区。因为区里面的数据块在物理上是连续的,所以全表扫描可以多块读。全表扫描不能跨区扫描,因为区与区之间的块物理上不一定是连续的。对于分区表,如果表中没有clob/blob字段,一个分区就是一个段,分区表扫描方式与非分区表扫描方式是一样的。
对一个非分区表进行并行扫描,其实就是同时扫描表中多个不同区,因为区与区之间的块物理上不连续,所以我们不需要担心扫描到相同数据块。
对一个分区表进行并行扫描,有两种方式。如果需要扫描多个分区,那么是以分区为粒度进行并行扫描的,这时如果分区数据不均衡,会严重影响并行扫描速度;如果只需要扫描单个分区,这时是以区为粒度进行并行扫描的。
如果表中有clob字段,clob会单独存放在一个段中,当全表扫描需要访问clob字段时,这时性能会严重下降,因此尽量避免在Oracle中使用clob。我们可以考虑将clob字段拆分为多个varchar2(4000)字段,或者将clob存放在nosql数据库中,例如mongodb。
一般的操作系统,一次I/O最多只支持读取或者写入1MB数据。数据块为8KB的时候,一次I/O最多能读取128个块。数据块为16KB的时候,一次I/O最多能读取64个块,数据块为32KB的时候,一次I/O最多能读取32个块。
如果表中有部分块已经缓存在buffer cache中,在进行全表扫描的时候,扫描到已经被缓存的块所在区时,就会引起I/O中断。如果一个表不同的区有大量块缓存在buffer cache中,这个时候,全表扫描性能会严重下降,因为有大量的I/O中断,导致每次I/O不能扫描1MB数据。
我们以测试表test为例,先查看测试表test有多少个区:
select EXTENT_ID, BLOCKS, BLOCK_ID
from DBA_EXTENTS
where SEGMENT_NAME = 'TEST'
and OWNER = 'SCOTT';
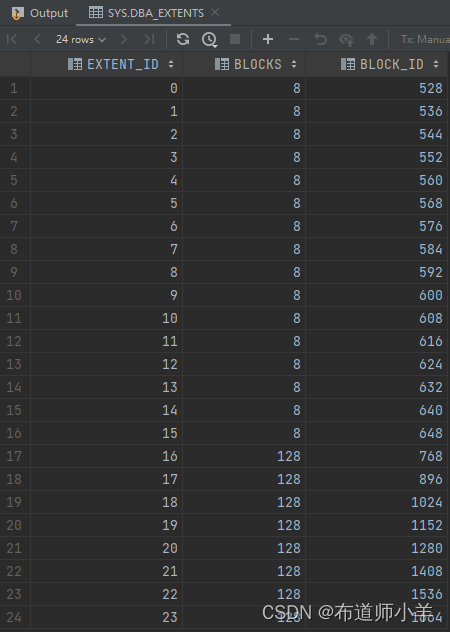
测试表test一共有24个区,而且每个区都没有超过128个块。正常情况下,对测试表test进行全表扫描需要进行24次多块读。
如果表正在发生大事务,在进行全表扫描的时候,还会从undo读取部分数据。从undo读取数据是单块读,这种情况下全表扫描效率非常低下。因此,我们建议使用批量游标的方式处理大事务。使用批量游标处理大事务还可以减少对undo的使用,防止事务失败回滚太慢。
Oracle行存储数据库在进行全表扫描时会扫描表中所有的列。
1.2、TABLE ACCESS BY USER ROWID
TABLE ACCESS BY USER ROWID表示直接用ROWID获取数据,单块读。该访问路径在Oracle所有的访问路径中性能是最好的。
我们以测试表test为例,运行下面SQL并且查看执行计划:
SQL> select * from test where rowid='AAASNJAAEAAAAJqAA3';
Execution Plan
----------------------------------------------------------
Plan hash value: 1358188196
-----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 97 | 1 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY USER ROWID| TEST | 1 | 97 | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------
在where条件中直接使用rowid获取数据就会使用该访问路径。
1.3、TABLE ACCESS BY ROWID RANGE
TABLE ACCESS BY ROWID RANGE表示ROWID范围扫描,多块读。因为同一个块里面的ROWID是连续的,同一个EXTENT里面的ROWID也是连续的,所以可以多块读。
SQL> select * from test where rowid>='AAASs5AAEAAB+SLAAA';
72462 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 3472873366
------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3651 | 345K| 186 (1)| 00:00:03 |
|* 1 | TABLE ACCESS BY ROWID RANGE| TEST | 3651 | 345K| 186 (1)| 00:00:03 |
------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access(ROWID>='AAASs5AAEAAB+SLAAA')
where条件中直接使用rowid进行范围扫描就会使用该执行计划。
1.4、TABLE ACCESS BY INDEX ROWID
TABLE ACCESS BY INDEX ROWID表示回表,单块读。
1.5、INDEX UNIQUE SCAN
INDEX UNIQUE SCAN表示索引唯一扫描,单块读。
对唯一索引或者对主键列进行等值查找,就会走INDEX UNIQUE SCAN。因为对唯一索引或者对主键列进行等值查找,CBO能确保最多只返回1行数据,所以这时可以走索引唯一扫描。
我们以scott账户中emp表为例,运行下面SQL并且查看执行计划:
SQL> select * from emp where empno=7369;
Execution Plan
----------------------------------------------------------
Plan hash value: 2949544139
-------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cos t(%CPU)| Time |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 38 | 1 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 38 | 1 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN | PK_EMP | 1 | | 0 (0)| 00:00:01 |
-------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("EMPNO"=7369)
因为empno是主键列,对empno进行等值访问,就走了INDEX UNIQUE SCAN。
INDEX UNIQUE SCAN最多只返回一行数据,只会扫描“索引高度”个索引块,在所有的Oracle访问路径中,其性能仅次于TABLE ACCESS BY USER ROWID。
1.6、INDEX RANGE SCAN
INDEX RANGE SCAN表示索引范围扫描,单块读,返回的数据是有序的(默认升序)。HINT: INDEX(表名/别名 索引名)。对唯一索引或者主键进行范围查找,对非唯一索引进行等值查找,范围查找,就会发生INDEX RANGE SCAN。等待事件为db file sequential read。
我们以测试表test为例,运行下面SQL并且查看执行计划:
SQL> select * from test where object_id=100;
Execution Plan
----------------------------------------------------------
Plan hash value: 3946039639
-------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 97 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| TEST | 1 | 97 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_ID | 1 | | 1 (0)| 00:00:01 |
-------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_ID"=100)
因为索引IDX_ID是非唯一索引,对非唯一索引进行等值查找并不能确保只返回一行数据,有可能返回多行数据,所以执行计划会进行索引范围扫描。
索引范围扫描默认是从索引中最左边的叶子块开始,然后往右边的叶子块扫描(从小到大),当检查到不匹配数据的时候,就停止扫描。
现在我们将过滤条件改为小于,并且对过滤列进行降序排序,查看执行计划:
SQL> select * from test where object_id<100 order by object_id desc;
98 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 1069979465
-------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost(%CPU)| Time |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 96 | 9312 | 4 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID | TEST | 96 | 9312 | 4 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN DESCENDING| IDX_ID | 96 | | 2 (0)| 00:00:01 |
-------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_ID"<100)
filter("OBJECT_ID"<100)
INDEX RANGE SCAN DECENDING表示索引降序范围扫描,从右往左扫描,返回的数据是降序显示的。
假设一个索引叶子块能存储100行数据,通过索引返回100行以内的数据,只扫描“索引高度”个索引块,如果通过索引返回200行数据,就需要扫描两个叶子块。通过索引返回的行数越多,扫描的索引叶子块也就越多,随着扫描的叶子块个数的增加,索引范围扫描的性能开销也就越大。如果索引范围扫描需要回表,同样假设一个索引叶子块能存储100行数据,通过索引返回1000行数据,只需要扫描10个索引叶子块(单块读),但是回表可能会需要访问几十个到几百个表块(单块读)。在检查执行计划的时候我们要注意索引范围扫描返回多少行数据,如果返回少量数据,不会出现性能问题;如果返回大量数据,在没有回表的情况下也还好;如果返回大量数据同时还有回表,这时我们应该考虑通过创建组合索引消除回表或者使用全表扫描来代替它。
1.7、INDEX SKIP SCAN
INDEX SKIP SCAN表示索引跳跃扫描,单块读。返回的数据是有序的(默认升序)。HINT: INDEX_SS(表名/别名 索引名)。当组合索引的引导列(第一个列)没有在where条件中,并且组合索引的引导列/前几个列的基数很低,where过滤条件对组合索引中非引导列进行过滤的时候就会发生索引跳跃扫描,等待事件为db file sequential read。
我们在测试表test上创建如下索引:
create index idx_ownerid on test(owner,object_id);
然后我们删除object_id列上的索引IDX_ID:
drop index idx_id;
我们执行如下SQL并且查看执行计划:
SQL> select * from test where object_id<100;
98 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 847134193
-------------------------------------------------------------------------------------
| Id |Operation | Name | Rows | Bytes | Cost(%CPU)| Time |
-------------------------------------------------------------------------------------
| 0 |SELECT STATEMENT | | 96 | 9312 | 100 (0)| 00:00:02
| 1 | TABLE ACCESS BY INDEX ROWID| TEST | 96 | 9312 | 100 (0)| 00:00:02
|* 2 | INDEX SKIP SCAN | IDX_OWNERID | 96 | | 97 (0)| 00:00:02
-------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_ID"<100)
filter("OBJECT_ID"<100)
从执行计划中我们可以看到上面SQL走了索引跳跃扫描。最理想的情况应该是直接走where条件列object_id上的索引,并且走INDEX RANGE SCAN。但是因为where条件列上面没有直接创建索引,而是间接地被包含在组合索引中,为了避免全表扫描,CBO就选择了索引跳跃扫描。
INDEX SKIP SCAN中有个SKIP关键字,也就是说它是跳着扫描的。那么想要跳跃扫描,必须是组合索引,如果是单列索引怎么跳?另外,组合索引的引导列不能出现在where条件中,如果引导列出现在where条件中,它为什么还跳跃扫描呢,直接INDEX RANGE SCAN不就可以了?再有,要引导列基数很低,如果引导列基数很高,那么它“跳”的次数就多了,性能就差了。
当执行计划中出现了INDEX SKIP SCAN,我们可以直接在过滤列上面建立索引,使用INDEX RANGE SCAN代替INDEX SKIP SCAN。
1.8、INDEX FULL SCAN
INDEX FULL SCAN表示索引全扫描,单块读,返回的数据是有序的(默认升序)。HINT: INDEX(表名/别名 索引名)。索引全扫描会扫描索引中所有的叶子块(从左往右扫描),如果索引很大,会产生严重性能问题(因为是单块读)。等待事件为db file sequential read。
它通常发生在下面3种情况:
- 分页语句。
- SQL语句有order by选项,order by的列都包含在索引中,并且order by后列顺序必须和索引列顺序一致。order by的第一个列不能有过滤条件,如果有过滤条件就会走索引范围扫描(INDEX RANGE SCAN)。同时表的数据量不能太大(数据量太大会走TABLE ACCESS FULL + SORT ORDER BY)。
我们有如下SQL:
select * from test order by object_id,owner;
我们创建如下索引(索引顺序必须与排序顺序一致,加0是为了让索引能存NULL):
create index idx_idowner on test(object_id,owner,0);
我们执行如下SQL并且查看执行计划:
SQL> select * from test order by object_id,owner;
72462 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 3870803568
-------------------------------------------------------------------------------------
| Id |Operation | Name | Rows | Bytes |Cost(%CPU)| Time |
-------------------------------------------------------------------------------------
| 0 |SELECT STATEMENT | | 73020 | 6916K|1338 (1)| 00:00:17 |
| 1 | TABLE ACCESS BY INDEX ROWID| TEST | 73020 | 6916K|1338 (1)| 00:00:17 |
| 2 | INDEX FULL SCAN | IDX_IDOWNER | 73020 | | 242 (1)| 00:00:03 |
-------------------------------------------------------------------------------------
在进行SORT MERGE JOIN的时候,如果表数据量比较小,让连接列走INDEX FULL SCAN可以避免排序。例子如下:
SQL> select / *+ use_merge(e,d) */
2 *
3 from emp e, dept d
4 where e.deptno = d.deptno;
14 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 844388907
-------------------------------------------------------------------------------------
| Id |Operation | Name | Rows | Bytes | Cost(%CPU)| Time |
-------------------------------------------------------------------------------------
| 0 |SELECT STATEMENT | | 14 | 812 | 6 (17)| 00:00:01 |
| 1 | MERGE JOIN | | 14 | 812 | 6 (17)| 00:00:01 |
| 2 | TABLE ACCESS BY INDEX ROWID| DEPT | 4 | 80 | 2 (0)| 00:00:01 |
| 3 | INDEX FULL SCAN | PK_DEPT | 4 | | 1 (0)| 00:00:01 |
|* 4 | SORT JOIN | | 14 | 532 | 4 (25)| 00:00:01 |
| 5 | TABLE ACCESS FULL | EMP | 14 | 532 | 3 (0)| 00:00:01 |
-------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("E"."DEPTNO"="D"."DEPTNO")
filter("E"."DEPTNO"="D"."DEPTNO")
当看到执行计划中有INDEX FULL SCAN,我们首先要检查INDEX FULL SCAN是否有回表。
如果INDEX FULL SCAN没有回表,我们要检查索引段大小,如果索引段太大(GB级别),应该使用INDEX FAST FULL SCAN代替INDEX FULL SCAN,因为INDEX FAST FULL SCAN是多块读,INDEX FULL SCAN是单块读,即使使用了INDEX FAST FULL SCAN会产生额外的排序操作,也要用INDEX FAST FULL SCAN代替INDEX FULL SCAN。
如果INDEX FULL SCAN有回表,大多数情况下,这种执行计划是错误的,因为INDEX FULL SCAN是单块读,回表也是单块读。这时应该走全表扫描,因为全表扫描是多块读。如果分页语句走了INDEX FULL SCAN然后回表,这时应该没有太大问题。
1.9、INDEX FAST FULL SCAN
INDEX FAST FULL SCAN表示索引快速全扫描,多块读。HINT:INDEX_FFS(表名/别名 索引名)。当需要从表中查询出大量数据但是只需要获取表中部分列的数据的,我们可以利用索引快速全扫描代替全表扫描来提升性能。索引快速全扫描的扫描方式与全表扫描的扫描方式是一样,都是按区扫描,所以它可以多块读,而且可以并行扫描。等待事件为db file scattered read,如果是并行扫描,等待事件为direct path read。
现有如下SQL:
select owner,object_name from test;
该SQL没有过滤条件,默认情况下会走全表扫描。但是因为Oracle是行存储数据库,全表扫描的时候会扫描表中所有的列,而上面查询只访问表中两个列,全表扫描会多扫描额外13个列,所以我们可以创建一个组合索引,使用索引快速全扫描代替全表扫描:
create index idx_ownername on test(owner,object_name,0);
我们查看SQL执行计划:
SQL> select owner,object_name from test;
72462 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 3888663772
-------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost(%CPU)| Time |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 73020 | 2210K| 79 (2)| 00:00:01 |
| 1 | INDEX FAST FULL SCAN| IDX_OWNERNAME | 73020 | 2210K| 79 (2)| 00:00:01 |
-------------------------------------------------------------------------------------
现有如下SQL:
select object_name from test where object_id<100;
该SQL有过滤条件,根据过滤条件where object_id<100过滤数据之后只返回少量数据,一般情况下我们直接在object_id列创建索引,让该SQL走object_id列的索引即可:
SQL> create index idx_id on test(object_id);
Index created.
SQL> select object_name from test where object_id 18 consistent gets
0 physical reads
0 redo size
2217 bytes sent via SQL*Net to client
485 bytes received via SQL*Net from client
8 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
98 rows processed
因为该SQL只查询一个字段,所以我们可以将select列放到组合索引中,避免回表:
SQL> create index idx_idname on test(object_id,object_name);
Index created.
我们再次查看SQL的执行计划:
SQL> select object_name from test where object_id 9 consistent gets
0 physical reads
0 redo size
2217 bytes sent via SQL*Net to client
485 bytes received via SQL*Net from client
8 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
98 rows processed
现有如下SQL:
select object_name from test where object_id>100;
以上SQL过滤条件是where object_id>100,返回大量数据,应该走全表扫描,但是因为SQL只访问一个字段,所以我们可以走索引快速全扫描来代替全表扫描。
SQL> select object_name from test where object_id>100;
72363 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 252646278
-----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 72924 | 2136K| 73 (2)| 00:00:01 |
|* 1 | INDEX FAST FULL SCAN| IDX_IDNAME | 72924 | 2136K| 73 (2)| 00:00:01 |
-----------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("OBJECT_ID">100)
大家可能会有疑问,以上SQL能否走INDEX RANGE SCAN呢?INDEX RANGE SCAN是单块读,SQL会返回表中大量数据,“几乎”会扫描索引中所有的叶子块。INDEX FAST FULL SCAN是多块读,会扫描索引中所有的块(根块、所有的分支块、所有的叶子块)。虽然INDEX RANGE SCAN与INDEX FAST FULL SCAN相比扫描的块少(逻辑读少),但是INDEX RANGE SCAN是单块读,耗费的I/O次数比INDEX FAST FULL SCAN的I/O次数多,所以INDEX FAST FULL SCAN性能更好。
在做SQL优化的时候,我们不要只看逻辑读来判断一个SQL性能的好坏,物理I/O次数比逻辑读更为重要。有时候逻辑读高的执行计划性能反而比逻辑读低的执行计划性能更好,因为逻辑读高的执行计划物理I/O次数比逻辑读低的执行计划物理I/O次数低。
在Oracle数据库中,INDEX FAST FULL SCAN是用来代替TABLE ACCESS FULL的。因为Oracle是行存储数据库,TABLE ACCESS FULL会扫描表中所有的列,而INDEX FAST FULL SCAN只需要扫描表中部分列,INDEX FAST FULL SCAN就是由Oracle是行存储这个“缺陷”而产生的。
如果我们启用了12c中的新特性IN MEMORY OPTION,INDEX FAST FULL SCAN几乎也没有用武之地了,因为表中的数据可以以列的形式存放在内存中,这时直接访问内存中的数据即可。
1.10、INDEX FULL SCAN(MIN/MAX)
INDEX FULL SCAN(MIN/MAX)表示索引最小/最大值扫描、单块读,该访问路径发生在 SELECT MAX(COLUMN)FROM TABLE 或者SELECT MIN(COLUMN)FROM TABLE等SQL语句中。
NDEX FULL SCAN(MIN/MAX)只会访问“索引高度”个索引块,其性能与INDEX UNIQUE SCAN一样,仅次于TABLE ACCESS BY USER ROWID。
现有如下SQL:
select max(object_id) from t;
该SQL查询object_id的最大值,如果object_id列有索引,索引默认是升序排序的,这时我们只需要扫描索引中“最右边”的叶子块就能得到object_id的最大值。现在我们查看该SQL的执行计划。
SQL> select max(object_id) from t;
Elapsed: 00:00:00.00
Execution Plan
----------------------------------------------------------
Plan hash value: 2448092560
-------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost(%CPU)| Time |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 186 (1)| 00:00:03 |
| 1 | SORT AGGREGATE | | 1 | 13 | | |
| 2 | INDEX FULL SCAN (MIN/MAX)| IDX_T_ID | 67907 | 862K| | |
-------------------------------------------------------------------------------------
Note
-----
- dynamic sampling used for this statement (level=2)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
2 consistent gets
0 physical reads
0 redo size
430 bytes sent via SQL*Net to client
419 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
现有另外一个SQL:
select max(object_id),min(object_id) from t;
该SQL要同时查看object_id的最大值和最小值,如果想直接从object_id列的索引获取数据,我们只需要扫描索引中“最左边”和“最右边”的叶子块就可以。在Btree索引中,索引叶子块是双向指向的,如果要一次性获取索引中“最左边”和“最右边”的叶子块,我们就需要连带的扫描“最大值”与“最小值”中间的叶子块,而本案例中,中间叶子块的数据并不是我们需要的。如果该SQL走索引,会走INDEX FAST FULL SCAN,而不会走INDEX FULL SCAN,因为INDEX FAST FULL SCAN可以多块读,而INDEX FULL SCAN是单块读,两者性能差距巨大(如果索引已经缓存在buffer cache中,走INDEX FULL SCAN与INDEX FAST FULL SCAN效率几乎一样,因为不需要物理I/O)。需要注意的是,该SQL没有排除object_id为NULL,如果直接运行该SQL,不会走索引。
SQL> select max(object_id),min(object_id) from t;
Elapsed: 00:00:00.02
Execution Plan
----------------------------------------------------------
Plan hash value: 2966233522
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 186 (1)| 00:00:03 |
| 1 | SORT AGGREGATE | | 1 | 13 | | |
| 2 | TABLE ACCESS FULL| T | 67907 | 862K| 186 (1)| 00:00:03 |
---------------------------------------------------------------------------
我们排除object_id为NULL,查看执行计划:
SQL> select max(object_id),min(object_id) from t where object_id is not null;
Elapsed: 00:00:00.01
Execution Plan
----------------------------------------------------------
Plan hash value: 3570898368
----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 33 (4)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 13 | | |
|* 2 | INDEX FAST FULL SCAN| IDX_T_ID | 67907 | 862K| 33 (4)| 00:00:01 |
----------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("OBJECT_ID" IS NOT NULL)
Note
-----
- dynamic sampling used for this statement (level=2)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
169 consistent gets
0 physical reads
0 redo size
501 bytes sent via SQL*Net to client
419 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
从上面的执行计划中我们可以看到SQL走了INDEX FAST FULL SCAN,INDEX FAST FULL SCAN会扫描索引段中所有的块,理想的情况是只扫描索引中“最左边”和“最右边”的叶子块。现在我们将该SQL改写为如下SQL。
select (select max(object_id) from t),(select min(object_id) from t) from dual;
我们查看后的执行计划:
SQL> select (select max(object_id) from t),(select min(object_id) from t) from dual;
Elapsed: 00:00:00.01
Execution Plan
----------------------------------------------------------
Plan hash value: 3622839313
-------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost(%CPU)| Time |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 2 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 13 | | |
| 2 | INDEX FULL SCAN (MIN/MAX)| IDX_T_ID | 67907 | 862K| | |
| 3 | SORT AGGREGATE | | 1 | 13 | | |
| 4 | INDEX FULL SCAN (MIN/MAX)| IDX_T_ID | 67907 | 862K| | |
| 5 | FAST DUAL | | 1 | | 2 (0)| 00:00:01 |
-------------------------------------------------------------------------------------
Note
-----
- dynamic sampling used for this statement (level=2)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
4 consistent gets
0 physical reads
0 redo size
527 bytes sent via SQL*Net to client
419 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
原始SQL因为需要1次性从索引中取得最大值和最小值,所以导致走了INDEX FAST FULL SCAN。我们将该SQL进行等价改写之后,访问了索引两次,一次取最大值,一次取最小值,从而避免扫描不需要的索引叶子块,大大提升了查询性能。
1.11、MAT_VIEW REWRITE ACCESS FULL
MAT_VIEW REWRITE ACCESS FULL表示物化视图全表扫描、多块读。因为物化视图本质上也是一个表,所以其扫描方式与全表扫描方式一样。如果我们开启了查询重写功能,而且SQL查询能够直接从物化视图中获得结果,就会走该访问路径。
现在我们创建一个物化视图TEST_MV:
SQL> create materialized view test_mv
2 build immediate enable query rewrite
3 as select object_id,object_name from test;
Materialized view created.
有如下SQL查询:
select object_id, object_name from test;
因为物化视图TEST_MV已经包含查询需要的字段,所以该SQL会直接访问物化视图TEST_MV:
SQL> select object_id,object_name from test;
72462 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 1627509066
-------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost(%CPU)| Time |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 67036 | 5171K| 65 (2)| 00:00:01 |
| 1 | MAT_VIEW REWRITE ACCESS FULL| TEST_MV | 67036 | 5171K| 65 (2)| 00:00:01 |
-------------------------------------------------------------------------------------
2、单块读与多块读
单块读与多块读这两个概念对于掌握SQL优化非常重要,更准确地说是单块读的物理I/O次数和多块读的物理I/O次数对于掌握SQL优化非常重要。
从磁盘1次读取1个块到buffer cache就叫单块读,从磁盘1次读取多个块到buffer cache就叫多块读。如果数据块都已经缓存在buffer cache中,那就不需要物理I/O了,没有物理I/O也就不存在单块读与多块读。
绝大多数的平台,一次I/O最多只能读取或者写入1MB数据,Oracle的块大小默认是8k,那么一次I/O最多只能写入128个块到磁盘,最多只能读取128个块到buffer cache。在判断哪个访问路径性能好的时候,通常是估算每个访问路径的I/O次数,谁的I/O次数少,谁的性能就好。在估算I/O次数的时候,我们只需要算个大概就可以了,没必要很精确。
3、为什么有时候索引扫描比全表扫描更慢
假设一个表有100万行数据,表的段大小为1GB。如果对表进行全表扫描,最理想的情况下,每次I/O都读取1MB数据(128个块),将1GB的表从磁盘读入buffer cache需要1 024次I/O。在实际情况中,表的段前16个extent,每个extent都只有8个块,每次I/O只能读取8个块,而不是128个块,表中有部分块会被缓存在buffer cache中,会引起I/O中断,那么将1GB的表从磁盘读入buffer cache可能需要耗费1 500次物理I/O。
从表中查询5万行数据,走索引。假设一个索引叶子块能存储100行数据,那么5万行数据需要扫描500个叶子块(单块读),也就是需要500次物理I/O,然后有5万条数据需要回表,假设索引的集群因子很小(接近表的块数),假设每个数据块存储50行数据,那么回表需要耗费1 000次物理I/O(单块读),也就是说从表中查询5万行数据,如果走索引,一共需要耗费大概1 500次物理I/O。如果索引的集群因子较大(接近表的总行数),那么回表要耗费更多的物理I/O,可能是3 000次,而不是1 000次。
根据上述理论我们知道,走索引返回的数据越多,需要耗费的I/O次数也就越多,因此,返回大量数据应该走全表扫描或者是INDEX FAST FULL SCAN,返回少量数据才走索引扫描。根据上述理论,我们一般建议返回表中总行数5%以内的数据,走索引扫描,超过5%走全表扫描。请注意,5%只是一个参考值,适用于绝大多数场景,如有特殊情况,具体问题具体分析。
4、DML对于索引维护的影响
在OLTP高并发INSERT环境中,递增列(时间,使用序列的主键列)的索引很容易引起索引热点块争用。递增列的索引会不断地往索引“最右边”的叶子块插入最新数据(因为索引默认升序排序),在高并发INSERT的时候,一次只能由一个SESSION进行INSERT,其余SESSION会处于等待状态,这样就引起了索引热点块争用。对于递增的主键列索引,我们可以对这个索引进行反转(reverse),这样在高并发INSERT的时候,就不会同时插入索引“最右边”的叶子块,而是会均衡地插入到各个不同的索引叶子块中,这样就解决了主键列索引的热点块问题。将索引进行反转之后,索引的集群因子会变得很大(基本上接近于表的总行数),此时索引范围扫描回表会有严重的性能问题。但是一般情况下,主键列都是等值访问,索引走的是索引唯一扫描(INDEX UNIQUE SCAN),不受集群因子的影响,所以对主键列索引进行反转没有任何问题。对于递增的时间列索引,我们不能对这个索引进行反转,因为经常会对时间字段进行范围查找,对时间字段的索引反转之后,索引的集群因子会变得很大,严重影响回表性能。遇到这种情况,我们应该考虑对表根据时间进行范围分区,利用分区裁剪来提升查询性能而不是在时间字段建立索引来提升性能。
在OLTP高并发INSERT环境中,非递增列索引(比如电话号码)一般不会引起索引热点块争用。非递增列的数据都是随机的(电话号码),在高并发INSERT的时候,会随机地插入到索引的各个叶子块中,因此非递增列索引不会引起索引热点块问题,但是如果索引太多会严重影响高并发INSERT的性能。
当只有1个会话进行INSERT时,表中会有1个块发生变化,有多少个索引,就会有多少个索引叶子块发生变化(不考虑索引分裂的情况),假设有10个索引,那么就有10个索引叶子块发生变化。如果有10个会话同时进行INSERT,这时表中最多有10个块会发生变化,索引中最多有100个块会发生变化(10个SESSION与10个索引相乘)。在高并发的INSERT环境中,表中的索引越多,INSERT速度越慢。对于高并发INSERT,我们一般是采用分库分表、读写分离和消息队列等技术来解决。
在OLAP环境中,没有高并发INSERT的情况,一般是单进程做批量INSERT。单进程做批量INSERT,可以在递增列上建立索引。因为是单进程,没有并发,不会有索引热点块争用,数据也是一直插入的索引中“最右边”的叶子块,所以递增列索引对批量INSERT影响不会太大。单进程做批量INSERT,不能在非递增列建立索引。因为批量INSERT几乎会更新索引中所有的叶子块,所以非递增列索引对批量INSERT影响很大。在OLAP环境中,事实(FACT)表没有主键,时间列一般也是分区字段,所以递增列上面一般是没有索引的,而电话号码等非递增列往往需要索引,为了提高批量INSERT的效率,我们可以在INSERT之前先禁止索引,等INSERT完成之后再重建索引。